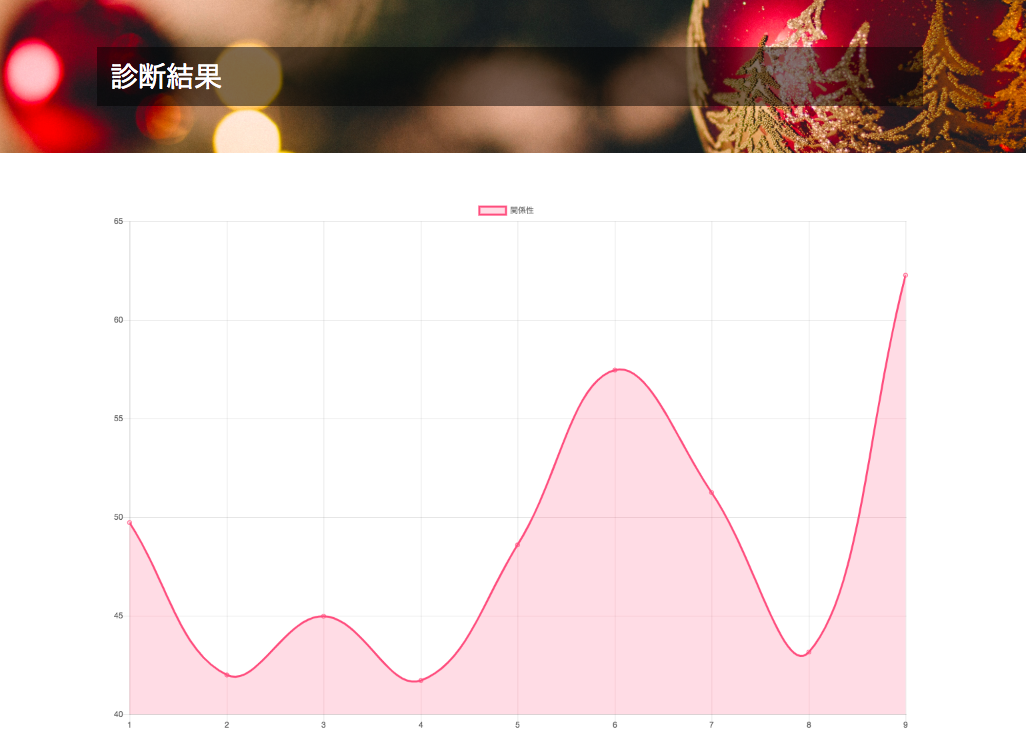
LINEのトーク履歴から相手のテンション推移をグラフ化
Githubはこちら
LINEのトーク履歴を取得
#!/usr/bin/python
# coding: UTF-8
import re
import json, codecs
from os import mkdir
from os.path import join, dirname, abspath, exists
from watson_developer_cloud import PersonalityInsightsV3
from os.path import join, dirname
import json
personality_insights = PersonalityInsightsV3(
version='YOURS',
iam_apikey='YOURS',
url='https://gateway.watsonplatform.net/personality-insights/api'
)
# テキストファイルの読み込み
text_file = input("テキストファイルを入れてください")
f = open(text_file)
data1 = f.read() # ファイル終端まで全て読んだデータを返す
f.close()
lines1 = data1.split('\n') # 改行で区切る(改行文字そのものは戻り値のデータには含まれない)
# 相手の名前を取得
a = 'E] '
b = 'とのトーク'
r = re.search(r'%s(.*?)?%s'%(a,b), lines1[0])
target_name = r.group(1)
# 相手のコメントor日付のみ取得
lines_2=[]
a = ' '
b = ' '
for line in lines1:
index = line.find("2018/") # 日付である
if index != -1:
lines_2.append(line)
else:
miyake_message = line.find("\t" + target_name) # それ以外のうち、時刻の後に"target_name"がきている
if miyake_message != -1:
lines_2.append(line)
else:
continue
# 必要ない部分を消す
lines_3=[]
rm_url = re.compile(r'https?://t.co/([A-Za-z0-9_]+)')
for line in lines_2:
line=re.sub(r'[0-3][0-9]:[0-6][0-9]', "", line)#時刻を削除
line=re.sub(r'[0-9]:[0-6][0-9]', "", line)#時刻を削除
line=re.sub(r'(月)|(火)|(水)|(木)|(金)|(土)|(日)', "", line)#曜日を削除1
line=re.sub(r'\(\)', "", line)#曜日を削除1
line=re.sub(target_name, "", line)#target_nameを削除
line=re.sub(r'\[スタンプ\]|\[写真\]|\[ファイル\]', "", line)#[スタンプ][写真][ファイル]を削除
line=re.sub(r'https?://[\w/:%#\$&\?\(\)~\.=\+\-…]+', "", line) #URLを削除
line=re.sub(r"\t", "", line)
lines_3.append(line)
lines_3 = lines_3[1:] #保存日時を削除
# 最初の日付から1週間ごとに分割(何も会話がない週は空欄にする予定)
import datetime
lines_4 = []
one_week_messages = []
a = datetime.date(2015, 4, 1)
for line in lines_3:
index = line.find("2018/") # 日付である
if index != -1:
dt = datetime.datetime.strptime(line, '%Y/%m/%d')
dt = datetime.date(dt.year, dt.month, dt.day)
if (dt-a).days >= 7: # 前から7日以上経過していたら現在のリストをlines_4に格納して初期化
a = dt
lines_4.append(one_week_messages)
one_week_messages = []
else:
one_week_messages.append(line)
# カサ増しをする(Personality Insightsは6読み取りに00単語以上が必須で、1200単語以上を推奨しているため)
for messages in lines_4:
number_of_words = 0
for message in messages:
number_of_words += len(message)
if number_of_words == 0:
additional_multi = 0
else:
additional_multi = 1200 // number_of_words +1
copied_messages_array = []
copied_messages = messages
for i in range(additional_multi):
copied_messages_array.extend(copied_messages)
messages.extend(copied_messages_array)
# 一番最初の空リスト削除
lines_5 = lines_4[1:]
それぞれをstring型に変更してgetPersonalityに入れる
## list -> string
def array_to_str(array):
s = '\n'.join(array)
return s
## 文字列からJSONデータ(ファイル)を取得
def strToJson(str):
lineHistoryArray = str.split('\n')
tmpList = []
for value in lineHistoryArray:
tmpList.append(dict(content=value,contenttype="text/plain",language='ja'))
lineHistoryDict = dict(contentItems = tmpList)
return json.dumps(lineHistoryDict, ensure_ascii=False)
## 文字列(str)から性格情報(JSON)を取得
def getPersonalityInsights(str):
## JSONデータを認識
profile = personality_insights.profile(
strToJson(str),
content_type='application/json',
consumption_preferences=True,
raw_scores=True
).get_result()
result = json.dumps(profile, indent=2)
result = json.loads(result)
return result["personality"][0]["children"][2]["raw_score"]
e_personality=[]
number_of_weekss = []
number_of_weeksss = 0
for line in lines_5:
str_line = array_to_str(line)
emotional_score = getPersonalityInsights(str_line)
e_personality.append(emotional_score)
for i in range(len(lines_5)):
number_of_weeksss += 1
number_of_weekss.append(number_of_weeksss)
return e_personality, number_of_weekss
Flask化
#!/usr/bin/env_python3
from flask import Flask, render_template, request, redirect, url_for, send_from_directory
import split_each_weeks_by_txt_3 as split_each_weeks_by_txt_3
app = Flask(__name__)
UPLOAD_FOLDER = './uploads'
ALLOWED_EXTENTION = 'txt'
app.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER
@app.route('/', methods=['GET'])
def index():
return render_template('index.html')
@app.route('/result', methods=['GET', 'POST'])
def result():
# key_word = request.files['txt_file']
e_personality, number_of_weekss = split_each_weeks_by_txt_3.main()
values_a = []
if request.method == 'POST':
for e_p in e_personality:
e_p = e_p * 100
values_a.append(e_p)
labels = [1, 2, 3, 4, 5, 6, 7, 8, 9]
#values_a = [10, 50 , 100, 35, 86, 72]
return render_template('result.html', labels=labels, values_a=values_a)
else:
return redirect(url_for('index'))
@app.route('/upload/<filenames>')
def upload_file(filename):
return send_from_directory(app.config['UPLOAD_FOLDER'], filename)
if __name__ == '__main__':
app.run(debug=True)
結果
top画面
result画面